Image Similarity Analysis
Nowadays, searching images by example has become an indispensable feature in any search engine. With the advent of Machine Learning, searching similar images can be achieved with Image Embedding and Auto-Encoder. However, searching similar images from thousands of images still require heavy computational power and resources. Therefore, for us, who lack expendable computing power and resources, need an alternative implementation to reduce the cost and complexity. With decent amount of Computing Power and Time Complexity, I am able to come up with an easy to implement Image Similarity Search with minimum computing resources.
Generally Speaking, the Similarity between two images is determinded by a set of characteristics, commonly known as Features. The primary features which are dominant in determining similarity are "Key Features".
It is assumed tha Key Features of an Image is deinfed by:
- Color
- Shape
- Texture
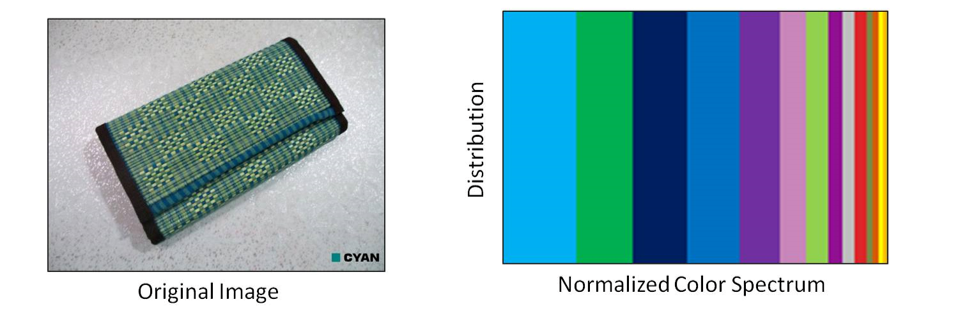
A Color Image has 3 Channels (Red, Green, Blue) with corresponding Intensity Distribution. However only distribution of dominant colors play an important role in determining the Image Color.Since it is difficult to analyze millions of colors, dominant colors are also normalized to defined sets ofcolors Global Color Spectrum. Color Spectrum is immune to Scale, Rotation and Translation.
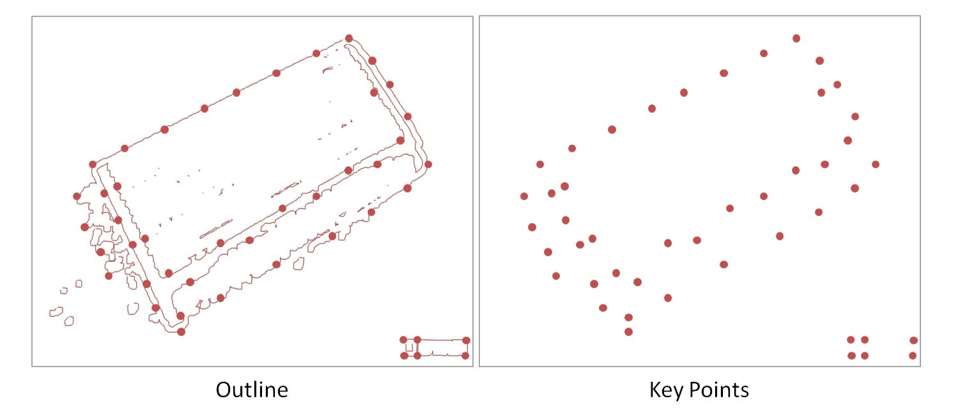
Shape of an Image can be defined by Outline (Contour) of an Image.

From the outline of the image, the Key Points are extracted as Shape Feature.

Texture of an image is roughly defined as spatial local color profile. Unlike global color spectrum, local color profile can be subjected to scale, translation and rotation.
Spatial Color Distribution specifies the distribution of dominant colors in specific regions (sections). Normally, a region is M x N Grid and in each region, dominant color is calculated.

Similarity between images is calculated by kNN (k Nearest Neighbour) distance and the distance is ranked to calculate the most similar images.
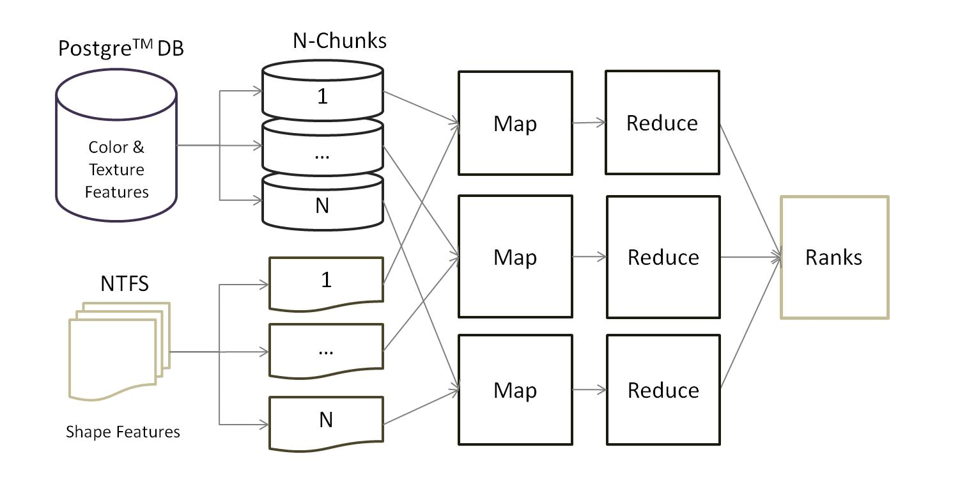
To reduce the work-load of computation for kNN in real time, Map-Reduce Pipeline is used.