Text Spotting and Recognition
I have developed a Bilingual (English and Myanmar) Text Spotting and Recogntion based on CRAFT Model (Naver) and CRNN-CTC Model (WandB).
Instead of End-to-End Text Recognition, I assume that it is better to use a modular approach, i.e., to train Text Spotting Model and Text Recognition Model seperately.
For Text Spotting Model, I think CRAFT (Naver) is more suitable because Myanmar Language, like Korean, is syllablic language, and it is trainable with Syllable Region Bounding Boxes.
For Text Recognition Model, CRNN-CTC Model is used. However, although token length of 32 Characters is enough for English, it is not nearly enough for Myanmar Language. Therefore, I have to come up with my own tokenization scheme for Myanmar Language, which I call "Visual Syllabic Tokenization".
Instead of tokenizing character by character, Myanmar Words are tokenized into Visually Seperable Syllables (Left to Right).

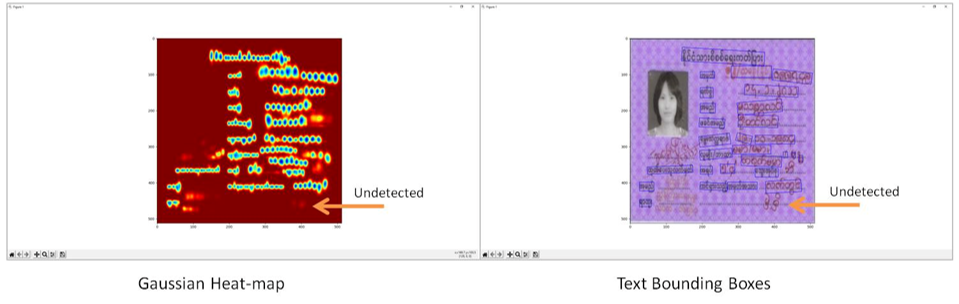
Bounding Boxes are generated for tokenized syllables, and Gaussian Heatmaps are calculated for Text Threshold Regions and Link Threshold Regions.
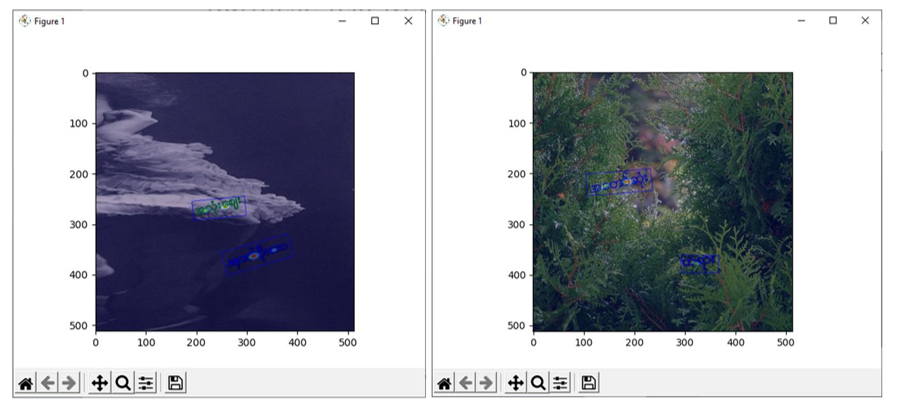
Bounding Boxes are generated for tokenized syllables, and Gaussian Heatmaps are calculated for Text Threshold Regions and Link Threshold Regions.
Around 80 millions text images are auto-generated to create a dataset for training CRNN-CTC Model.
